После первого прототипа дело o.t. застопорилось и неспроста.
Я начал повторять шаги, по которым до меня прошло уже много людей и коллективов, а с коллективами тягаться смысла нет.
Поэтому всякие плюшки типа аналога xpath или применения relaxng теперь кажутся неинтересными.
Со встраиванием языков программирования тоже проблема. Получается, что нет возможности встроить языки в шаблонизатор на уровне библиотеки и необязательного компонента.
Уже на уровне сканнера символов сталкиваемся с необходимостью двух различных обработчиков одного и того же символа, что само по себе лишает сканнер обероновской простоты.
Возможно на этом этапе стоит оформить сканнер и парсер по-другому.
Что тут можно предложить?
Первой на ум приходит мысль о модели производитель-потребитель. Сканнер становится нерасширяемым и монолитным и потребляет любой символ, даже тот, который ему незнаком. Минус очевиден, вся работа по осознанию семантики прочитанного становится задачей потребителя, что не очень хорошо с точки зрения разделения ответственности.
Второй способ довольно банален, монолитный парсер со сменными стратегиями разбора символов. Сканнер включает в себя сразу все возможные символы и предопределенные идентификаторы. Минус очевиден, возможные интерференции между синтаксисами языков внутри сканнера. Сложный компилятор с кучей дублирующегося по сути кода для разных режимов разбора, что почти не решается шаблонизацией или обобщением. Просто чуть разный, но однообразный код.
Третий способ полностью противоречит исходному желанию органично встроить исполняемый код в шаблон, мне придётся реализовать код в шаблонах как полностью отдельную сущность и разделять их с шаблоном уже на уровне текстового представления. Удобный, но антиконцептуальный способ.
Одно понятно, задача нетривиальная и малой кровью переиспользования существующих компиляторов leaf/lomo как мне кажется нерешаема. Может быть, для начала стоит перевести на общие рельсы имеющиеся системы, что в целом равносильно их переписыванию.
Первый прототип языка, парсера и объектной модели готов, подробности в вики.
По результату тестов можно отметить, что неявная квалификация даже в контексте текстовых человекочитаемых шаблонов есть фича неоднозначная.
В остальном всё довольно просто прошло, парсер -> объектная модель -> контекст. Даже немного боязно, не упустил ли чего за кажущейся простотой.
Сомнения вызывает точка, как разделитель в квалификаторе, она не позволяет использовать точку, как часть идентификатора, хотя в роли квалификатора точка довольно органично смотрится.
Сегодняшний формат выглядит примерно так:
В последнем варианте двоеточие смотрится неплохо, как в xml namespace, но это сразу убивает возможность использования двоеточия, как негромоздкого символа, открывающего содержимое объекта.
UPD: Всё же не смог пожертвовать точкой в идентификаторе и на свежую голову придумал разделитель вместо точки: ~.
module~class(id): content;
Конечно, пока никаких языков программирования встроить не требовалось, да и задача постепенно усложняется, так как встраивание требует модификации парсера, что может серьёзно повредить его, простой как сапог, сути.
Возможно, встраивание ЯП должно выглядеть иначе, чем задумывалось в посте с рассуждениями.
Почему сначала класс объекта, а потом необязательный идентификатор (имя)?
Потому что шаблон принципиально работает с объектом еще до его создания, то есть, на самом деле шаблон для разработчика и для шаблонизатора должен формировать новый объект из заданного класса. Зачастую, этого достаточно, а если недостаточно, то уже можно обращаться к конкретному объекту.
Как будет обеспечиваться модульность шаблонов?
Скорее всего, модульность шаблонов будет обеспечиваться таким же образом, как и в LOMO, то есть, вложенных шаблонов не будет, один шаблон - одна импортируемая сущность. Что не исключает возможности группировки шаблонов в подсистемы чисто организационно, на уровне файловой системы и полного квалификатора имени. Так же возможно будут экспортированные константы и объекты внутри сущностей (например, стандартные аттрибуты html).
Шаблоны декларативные или императивные?
Описание шаблона мультипарадигменное, тут и декларативная часть, и императивная часть и работа с контекстом, который каждый раз меняется под действием самого шаблона.
Процедуры и модульность внутри LEAF, импорт юнитов в LOMO?
Так как менять языки не хочется, скорее всего импорт из любого модуля будет возможен на этапе выполнения шаблона. Допустим это будет выглядеть так:
CORE.TEMPLATE(my-little-tree):
CHESS:
DO! IMPORT Strings
PROCEDURE Invert
VAR i+, o- STRING
BEGIN
o := i[\LEN i .. 0] (* range-нотации пока нет в LEAF *)
END Invert
VAR s STRING
BEGIN
Invert(o: "K F G", i -> s)
THIS: move = s;
END;
CALC!
VAR x INTEGER
PROCESS
2 -> x
x ^ 2 -> THIS number;
END;
;
;
Громоздко!
императивный код -> декларативный код -> шаблонный код, чем дальше тем хуже. Но попробовать стоит. Конечно, для поддержки инструкций шаблонов внутри встраиваемых языков их компиляторы придётся доработать, но формально это останутся те же языки с полным набором фич. Заодно можно попробовать наконец-то сделать обобщенную кодовую базу для всех языков.
Вернулся к обдумыванию применения LOMO и LEAF в качестве языка для описания объектов и процесса их построения, проще говоря, в качестве шаблонизатора.
Основная идея такая. Определяется некий контекст. Пока неважно какой, главное, в нем возможно создание объектов и их сохранение после завершения работы условного шаблонизатора.
Объекты представляют собой суть ссылку на класс и любое пользовательское содержимое, выраженное в форме составных типов MAP, LIST и, возможно, SET. Это даёт возможность описывать всевозможные отношения объектов и их свойства.
Важным свойством шаблонизатора будет возможность обращения к данным, которые размещены в контексте.
А еще более важным свойством будет являться возможность описывать императивный и декларативный код (на LEAF и LOMO, соответственно) непосредственно в теле шаблона, и такой код будет полностью легально создавать куски шаблона, менять свойства объектов и обращаться к данным в контексте.
Долго пришлось подумать над базовой концепцией шаблонизатора, которая позволила бы реализовать подобные возможности. Эта концепция, в общем, проста. Шаблон будет компилируемым. А вариация синтаксиса для описания объектов будет представлять собой то, что могло бы получиться у авторов XML, если бы они знали про Оберон.
core.template(my-perfect-page):
core.import! context html;
html.body(root):
br: enhanced;
br
br:
type: page;
fp = 344H;
;
`ffe`
para(see-my-text):
`first i was like`
bold: `smth`;
`, but then i `
italic: `lol'd`;
;
table:
len = context.len;
do!
var i integer
begin
while i < context.len do
this:
tr: hidden;
text = @see-my-text;
;
parent:
count = i + 1;
;
end
end;
;
;
;
Вполне вероятно, это будет выглядеть вот так. Капс скорее всего тоже будет применён (хотя кто знает).
Итак, что мы видим: шаблон представляет собой вариацию на тему модуля Оберона. Базовые правила описания объектов: класс (существующий, импортированный, стандартный или вновь созданный) (core.template, core.import, html.body, br и т.д.), затем опциональный идентификатор конкретного объекта (для модуля обязательный), потом модификатор доступа к содержимому: : - обычное содержимое, ! - специальное (мета)содержимое, = - уникальное (в рамках родительского объекта) содержимое. Возможно также описывать объекты заданного класса без содержимого. Особенностью будет необязательная квалификация классов внутри объекта с классом, импортированным из других шаблонов. Для html-шаблонов это будет немаловажным фактом.
Внутреннее содержимое объекта определяется как перечисление идентификаторов классов объектов и управление содержимым этих объектов. Кроме этого, содержимым объектов может быть любая константа текстового, числового или любого другого допустимого в LEAF/LOMO простого типа. Возможно имеет смысл непосредственно представлять любой объект как аналог модуля LOMO, но непонятно, как быть с императивными вставками. Отдельно рассматривается возможность использования в качестве содержимого ссылок на объекты по идентификатору.
Данный пример технической части является лишь наброском и возможно будет изменен, но базовая концепция постепенно формируется в прототип. Так, исполнение кода внутри шаблона будет доступно при его генерации. В принципе, этот код будет ничем не ограничен, но в нем будут доступны объекты, внутри которых он был вызван таким образом внутри кода будет возможность создания объектов контекста.
В примере был выбран шаблон html как наиболее шаблонизируемого языка, так как создание html из шаблонов это довольно важная часть работы шаблонизаторов вообще.
Результатом работы шаблонизатора над примером будет дерево объектов, которое может быть легко оттранслировано в html, провалидировано по требуемым правилам и так далее.
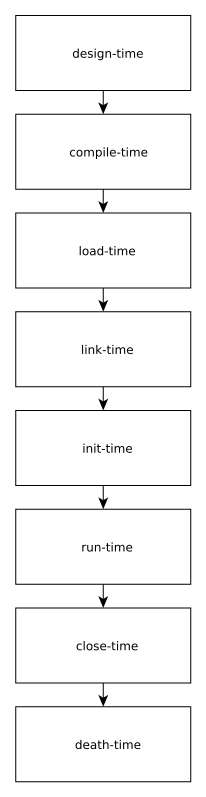
В дополнение необходимо отметить, что можно обоснованно выделить design-time в отдельную категорию, но не как процесс в голове разработчика, а чисто утилитарно, опираясь на процесс кодирования. Здесь можно описать автокомплит, автоподсветку (как уже реализованные программы), программирование макросов ide, генерацию схем БД и ДРАКОН-схем, и так далее. То есть, уточненная последовательность одной итерации жизненного цикла программы будет представлена как: design-time -> compile-time -> load-time -> link-time -> init-time -> run-time -> close-time -> death-time.